¿Son los modelos fundacionales para datos tabulares mejores que gradient boosting para riesgo crediticio? Los resultados son claros. Código completo y notebook reproducible: Trees vs TabPFN en Colab.
// La revolución de IA que se saltó las tablas
Pasamos años organizando el mundo desordenado en hojas de cálculo limpias, solo para ver a la revolución de IA funcionar para el mundo desordenado.
Yo construyo modelos de riesgo crediticio. Mis datos viven y mueren en una tabla. Y les puedo decir de primera mano: una enorme parte del trabajo no es modelar. Es convertir información salvajemente heterogénea en features estructurados que el ML tradicional pueda digerir.
Así que cuando un modelo fundacional para tablas finalmente apareció, tuve que probarlo donde me importa: en datos de crédito.
// TabPFN: Un Modelo Fundacional para Datos Tabulares
Ya era hora. Cuando entrenas XGBoost (el rey actual de las tablas), le enseñas al algoritmo a reconocer patrones para ese dataset específico. El modelo nunca ha visto otro dataset y empieza desde cero.
Flujo de trabajo tradicional:
Ingestar datos -> Limpiar datos -> Feature engineering -> Ajuste de Hiperparámetros -> Entrenamiento del Modelo -> Inferencia del Modelo -> Evaluación del modelo
Aquí llega TabPFN. Un Transformer pre-entrenado en MILLONES de datasets tabulares sintéticos diferentes que hace la pregunta: dados estas filas de entrenamiento Y sus etiquetas, ¿cuáles son las mejores etiquetas para estas nuevas filas? Tu variable objetivo se convierte en lo que los LLMs tratan como el siguiente token, una simple predicción.
Nuevo flujo de trabajo:
Ingestar datos -> Limpiar datos -> Inferencia del Modelo -> Evaluación del Modelo
En inferencia, TabPFN trata tus datos como contexto. De la misma forma que un LLM trata el prompt. Procesa todo y genera sus predicciones. Sin preprocesamiento, sin creación de features.
// Probando TabPFN en Datos de Riesgo Crediticio
Para este experimento, usé el dataset de Riesgo Crediticio de Kaggle.
Lo que hice:
- Eliminar features con fuga de datos: no importa qué tan bueno o de frontera sea tu modelo, NO predecir con el futuro.
- Darle ventaja a los árboles: Buenos hiperparámetros, preprocesamiento. Todo lo necesario para ganar.
TabPFN solo recibió los datos. Sin ayuda de mi parte:
clf = TabPFNClassifier()
clf.fit(X_train, y_train)Compara eso con los cientos de líneas de código de preprocesamiento para modelos basados en árboles, y los árboles ya son los algoritmos menos exigentes en cuanto a preparación de datos.
// Resultados: TabPFN vs XGBoost vs LightGBM
Cada modelo fue entrenado en el set completo de entrenamiento y el holdout fue de 2,000 muestras.
Validación cruzada de cinco pliegues:
| Modelo | ROC AUC | Std |
|---|---|---|
| TabPFN-2.5 | 0.8728 | ± 0.0064 |
| LightGBM | 0.8466 | ± 0.0083 |
| XGBoost | 0.8377 | ± 0.0058 |
Confirmación en holdout:
| Modelo | ROC AUC | PR AUC |
|---|---|---|
| TabPFN-2.5 | 0.8726 | 0.7738 |
| LightGBM | 0.8495 | 0.7398 |
| XGBoost | 0.8469 | 0.7293 |
TabPFN ganó en todas las métricas. Una diferencia de 2-3 puntos de AUC es significativa en riesgo crediticio, donde los modelos se comparan al tercer decimal.
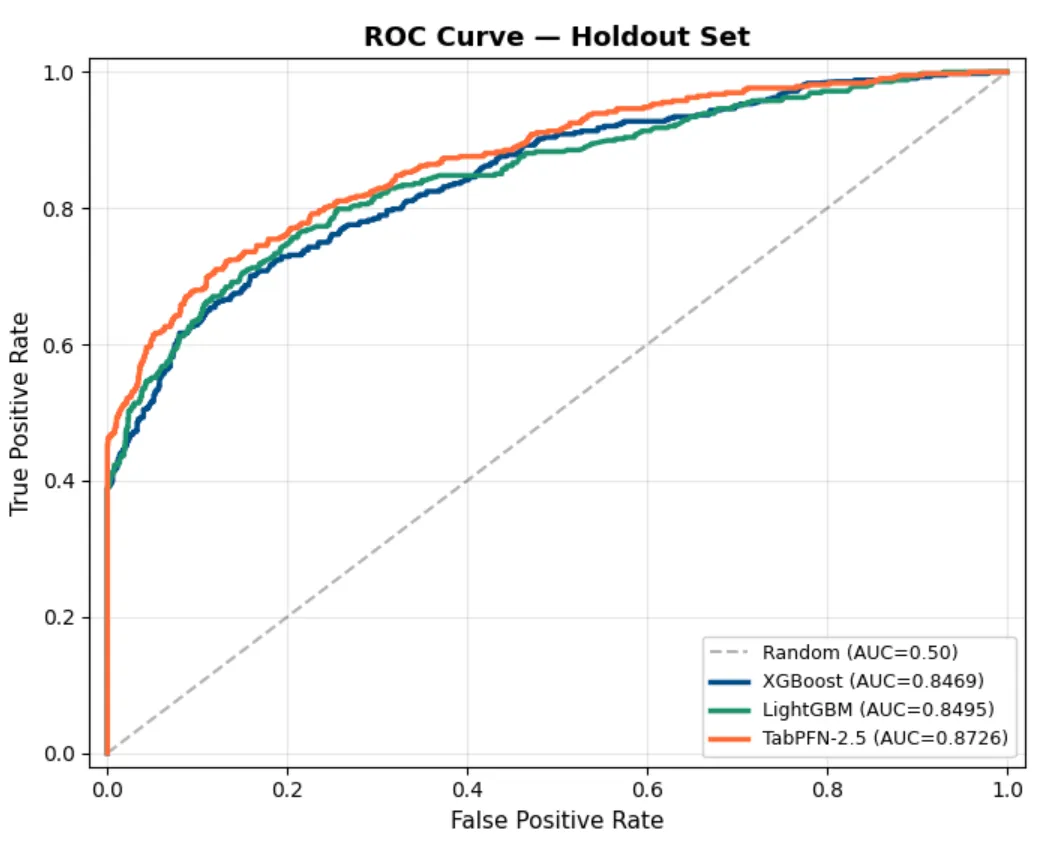
El costo: TabPFN tardó 5-12 segundos por pliegue versus 0.07-0.30 segundos para los árboles. Una penalización de latencia de 40-100x.
// Por Qué la Calibración Importa Más que el AUC en Riesgo Crediticio
La calibración permite que los modelos generen probabilidades reales (si están bien calibrados). En Riesgo Crediticio, te DEBE importar porque si tu modelo te dice una probabilidad de default del 15%, realmente quieres OBSERVAR una tasa de default del 15%.
El AUC es un concurso de belleza, te dice que el modelo puede rankear prestatarios. Pero rankear no es suficiente. Pricing, provisiones de pérdidas, reservas de capital, stress testing regulatorio — todo esto depende de que la probabilidad de default predicha sea precisa, no solo ordinalmente correcta.
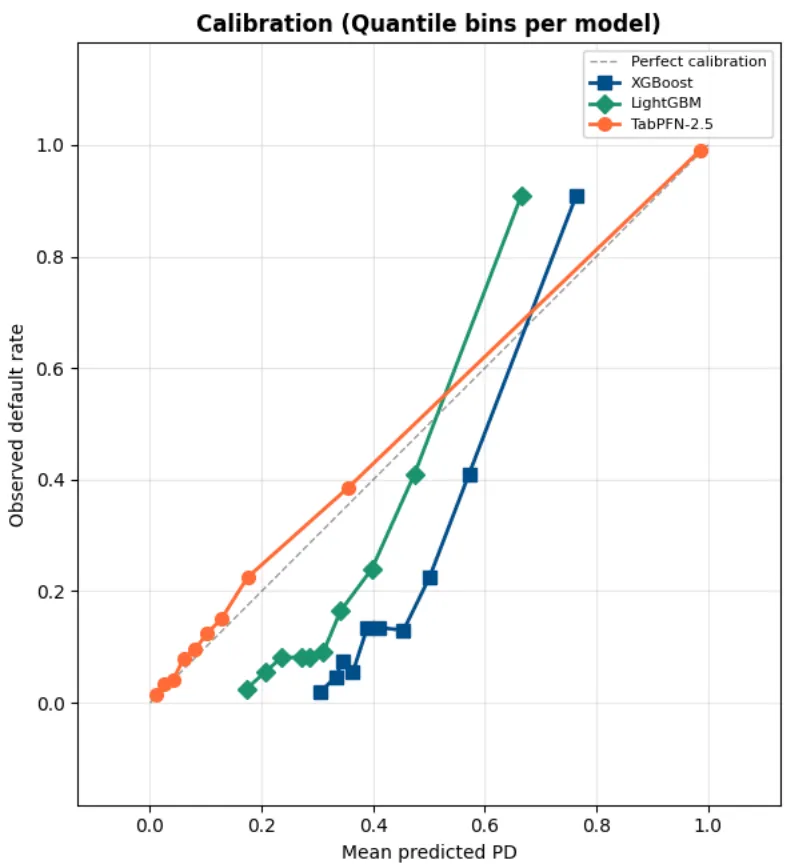
TabPFN entrega probabilidades calibradas de fábrica. Sin regresión isotónica. Sin escalado de Platt. Sin correcciones post-hoc. Las probabilidades son correctas porque el modelo hace inferencia bayesiana, promediando sobre posibles explicaciones en lugar de comprometerse con una sola estructura de árbol.
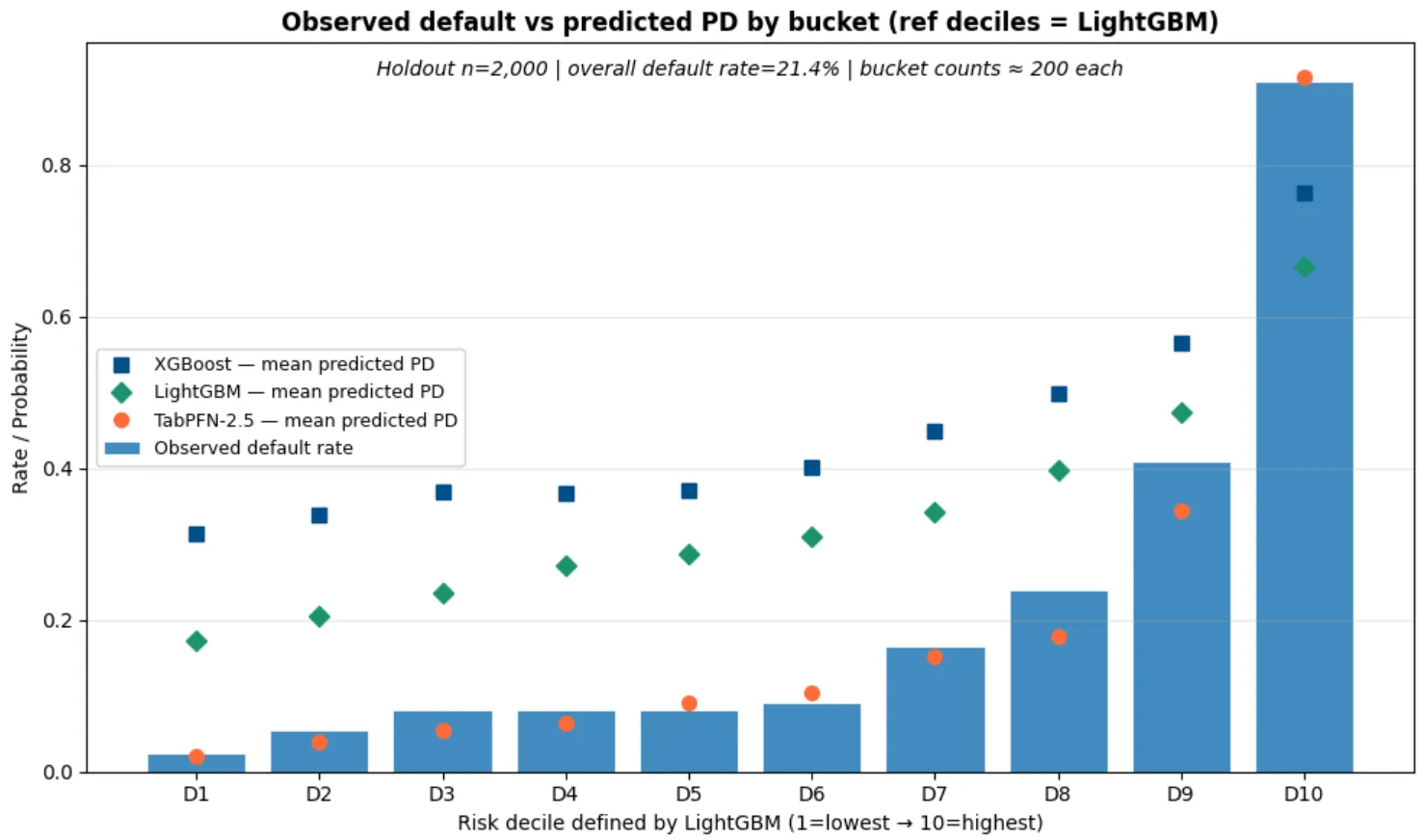
Mira las predicciones de los modelos basados en árboles. Constantemente más altas que la tasa de default observada, haciendo los modelos mucho más conservadores y salvajemente descalibrados.
// Dónde Falla TabPFN: Escala y Latencia
Antes de reemplazar todos tus modelos, piensa en esto:
-
Límites de tamaño de muestra: TabPFN-2.5 maneja hasta ~50,000 muestras y 2,000 features. Eso cubre muchos casos de uso en modelado crediticio: fintechs en etapa temprana, portafolios de nicho, segmentos con historial limitado. Pero si estás scoring un portafolio hipotecario de 10 millones de filas, necesitarás estrategias de muestreo o un enfoque híbrido.
-
Velocidad: En decisiones en tiempo real a escala, la latencia importa. Prior Labs está trabajando en un motor de destilación que promete latencia nivel árboles con precisión de modelo fundacional, pero aún no es open source.
Y sobre todo, este fue UN solo dataset. Deberías probar TabPFN en tus datos, con tus features, contra tu pipeline ajustado.
// Qué Significa TabPFN para el Modelado de Riesgo Crediticio
Un modelo fundacional acaba de entregar un rendimiento sólido en riesgo crediticio sin conocimiento del dominio, sin feature engineering y sin ajuste de hiperparámetros.
Aún no está listo para producción. Los límites de tamaño de muestra y las preocupaciones de latencia son reales.
La experiencia de dominio se queda por ahora: traducir outputs del modelo en decisiones de negocio, satisfacer requisitos de riesgo de modelo, saber qué features tienen fuga; eso se queda.